In our planned series of publications about the Semantic Web and its Apps today Hakia is our 3rd featured company.
Hakia.com, just like Freebase and Powerset is also heavily relying on Semantic technologies to produce and deliver hopefully better and meaningful results to its users.
Hakia is building the Web’s new “meaning-based” (semantic) search engine with the sole purpose of improving search  relevancy and interactivity, pushing the current boundaries of Web search. The benefits to the end user are search efficiency, richness of information, and time savings. The basic promise is to bring search results by meaning match – similar to the human brain’s cognitive skills – rather than by the mere occurrence (or popularity) of search terms. Hakia’s new technology is a radical departure from the conventional indexing approach, because indexing has severe limitations to handle full-scale semantic search.
relevancy and interactivity, pushing the current boundaries of Web search. The benefits to the end user are search efficiency, richness of information, and time savings. The basic promise is to bring search results by meaning match – similar to the human brain’s cognitive skills – rather than by the mere occurrence (or popularity) of search terms. Hakia’s new technology is a radical departure from the conventional indexing approach, because indexing has severe limitations to handle full-scale semantic search.
Hakia’s capabilities will appeal to all Web searchers – especially those engaged in research on knowledge intensive subjects, such as medicine, law, finance, science, and literature. The mission of hakia is the commitment to search for better search.
Here are the technological differences of hakia in comparison to conventional search engines.
QDEX Infrastructure
- hakia’s designers broke from decades-old indexing method and built a more advanced system called QDEX (stands for Query Detection and Extraction) to enable semantic analysis of Web pages, and “meaning-based” search.Â
- QDEX analyzes each Web page much more intensely, dissecting it to its knowledge bits, then storing them as gateways to all possible queries one can ask.
- The information density in the QDEX system is significantly higher than that of a typical index table, which is a basic requirement for undertaking full semantic analysis.
- The QDEX data resides on a distributed network of fast servers using a mosaic-like data storage structure.
- QDEX has superior scalability properties because data segments are independent of each other.
SemanticRank Algorithm
- SemanticRank algorithm of hakia is comprised of innovative solutions from the disciplines of Ontological Semantics, Fuzzy Logic, Computational Linguistics, and Mathematics.Â
- Designed for the expressed purpose of higher relevancy.
- Sets the stage for search based on meaning of content rather than the mere presence or popularity of keywords.
- Deploys a layer of on-the-fly analysis with superb scalability properties.
- Takes into account the credibility of sources among equally meaningful results.
- Evolves its capacity of understanding text from BETA operation onward.
In our tests we’ve asked Hakia three English-language based questions:
Why did the stock market crash? [ http://www.hakia.com/search.aspx?q=why+did+the+stock+market+crash%3F ]
Where do I get good bagels in Brooklyn? [ http://www.hakia.com/search.aspx?q=where+can+i+find+good+bagels+in+brooklyn ]
Who invented the Internet? [ http://www.hakia.com/search.aspx?q=who+invented+the+internet ]
It basically returned intelligent results for all. For example, Hakia understood that, when we asked “why,” I would be interested in results with the words “reason for”–and produced some relevant ones.Â
Hakia is one of the few promising Alternative Search Engines as being closely watched by Charles Knight at his blog AltSearchEngines.com, with a focus on natural language processing methods to try and deliver ‘meaningful’ search results. Hakia attempts to analyze the concept of a search query, in particular by doing sentence analysis. Most other major search engines, including Google, analyze keywords. The company believes that the future of search engines will go beyond keyword analysis – search engines will talk back to you and in effect become your search assistant. One point worth noting here is that, currently, Hakia still has some human post-editing going on – so it isn’t 100% computer powered at this point and is close to human-powered search engine or combination of the two.
They hope to provide better search results with complex queries than Google currently offers, but they have a long way to catch up, considering Google’s vast lead in the search market, sophisticated technology, and rich coffers. Hakia’s semantic search technology aims to understand the meaning of search queries to improve the relevancy of the search results.
Instead of relying on indexing the web or on the popularity of particular web pages, as many search engines do, hakia tries to match the meaning of the search terms to mimic the cognitive processes of the human brain.
“We’re mainly focusing on the relevancy problem in the whole search experience,†said Dr. Berkan in an interview Friday. “You enter a question and get better relevancy and better results.â€
Dr. Berkan contends that search engines that use indexing and popularity algorithms are not as reliable with combinations of four or more words since there are not enough statistics available on which to base the most relevant results.
“What we are doing is an ultimate approach, doing meaning-based searches so we understand the query and the text, and make an association between them by semantic analysis,†he said.
Analyzing whole sentences instead of keywords would indefinitely increase the cost to the company to index and process the world’s information. The case is pretty much the same with Powerset where they are also doing deep contextual analysis on every sentence on every web page and is publicly known fact they have higher cost for indexing and analyzing than Google. Taking into consideration that Google is having more than 450,000 servers in several major data centers and hakia’s indexing and storage costs might be even higher the approach they are taking might cost their investors a fortune to keep the company alive.
It would be interesting enough to find out if hakia is also building their architecture upon the Hbase/Hadoop environment just like Powerset does.Â
In the context of indexing and storing the world’s information it worth mentioning that there is yet another start-up search engine called Cuill that’s claiming to have invented a technology for cheaper and faster indexation than Google’s. Cuill claims that their indexing costs will be 1/10th of Google’s, based on new search architectures and relevance methods.
Speaking also for semantic textual analysis and presentation of meaningful results NosyJoe.com is a great example of both, yet it seems it is not going to index and store the world’s information and then apply the contextual analysis to, but rather than is focusing on what is quality and important for the people participating in their social search engine.Â
A few months ago Hakia launched a new social feature called “Meet Others” It will give you the option, from a 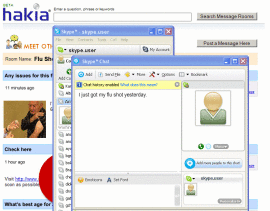 search results page, to jump to a page on the service where everyone who searches for the topic can communicate.
search results page, to jump to a page on the service where everyone who searches for the topic can communicate.
For some idealized types of searching, it could be great. For example, suppose you were searching for information on a medical condition. Meet Others could connect you with other people looking for info about the condition, making an ad-hoc support group. On the Meet Others page, you’re able to add comments, or connect directly with the people on the page via anonymous e-mail or by Skype or instant messaging.
On the other hand implementing social recommendations and relying on social elements like Hakia’s Meet the Others feature one needs to have huge traffic to turn that interesting social feature into an effective information discovery tool. For example Google with its more than 500 million unique searchers per month can easily beat such social attempts undergone by the smaller players if they only decide to employ, in one way or another, their users to find, determine the relevancy, share and recommend results others also search for. Such attempts by Google are already in place as one can read over here: Is Google trying to become a social search engine.
Reach
According to Quantcast, Hakia is basically not so popular site and is reaching less than 150,000 unique visitors per month. Compete is reporting much better numbers – slightly below 1 million uniques per month. Considering the fact the search engine is still in its beta stage these numbers are more than great. Analyzing further the traffic curve on both measuring sites above it appears that the traffic hakia gets is sort of campaign based, in other words generated due to advertising, promotion or PR activity and is not permanent organic traffic due to heavy usage of the site.
The People
Founded in 2004, hakia is a privately held company with headquarters in downtown Manhattan. hakia operates globally with teams in the United States, Turkey, England, Germany, and Poland.
The Founder of hakia is Dr. Berkan who is a nuclear scientist with a specialization in artificial intelligence and fuzzy logic.  He is the author of several articles in this area, including the book Fuzzy Systems Design Principles published by IEEE in 1997. Before launching hakia, Dr. Berkan worked for the U.S. Government for a decade with emphasis on information handling, criticality safety and safeguards. He holds a Ph.D. in Nuclear Engineering from the University of Tennessee, and B.S. in Physics from Hacettepe University, Turkey. He has been developing the company’s semantic search technology with help from Professor Victor Raskin of PurdueUniversity, who specializes in computational linguistics and ontological semantics, and is the company’s chief scientific advisor.
He is the author of several articles in this area, including the book Fuzzy Systems Design Principles published by IEEE in 1997. Before launching hakia, Dr. Berkan worked for the U.S. Government for a decade with emphasis on information handling, criticality safety and safeguards. He holds a Ph.D. in Nuclear Engineering from the University of Tennessee, and B.S. in Physics from Hacettepe University, Turkey. He has been developing the company’s semantic search technology with help from Professor Victor Raskin of PurdueUniversity, who specializes in computational linguistics and ontological semantics, and is the company’s chief scientific advisor.
Dr. Berkan resisted VC firms because he worried they would demand too much control and push development too fast to get the technology to the product phase so they could earn back their investment.
When he met Dr. Raskin, he discovered they had similar ideas about search and semantic analysis, and by 2004 they had laid out their plans.
They currently have 20 programmers working on building the system in New York, and another 20 to 30 contractors working remotely from different locations around the world, including Turkey, Armenia, Russia, Germany, and Poland.
The programmers are developing the search engine so it can better handle complex queries and maybe surpass some of its larger competitors.
Management
- Dr. Riza C. Berkan, Chief Executive Officer
- Melek Pulatkonak, Chief Operating Officer
- Tim McGuinness, Vice President, Search
- Stacy Schinder, Director of Business Intelligence
- Dr. Christian F. Hempelmann, Chief Scientific Officer
- John Grzymala, Chief Financial Officer
Board of Directors
- Dr. Pentti Kouri, Chairman
- Â Dr. Riza C. Berkan, CEO
- John Grzymala
- Anuj Mathur, Alexandra Global Fund
- Bill Bradley, former U.S. Senator
- Murat Vargi, KVK
- Ryszard Krauze, Prokom Investments
Advisory Board
- Prof. Victor Raskin (Purdue University)
- Prof. Yorick Wilks, (Sheffield University, UK)
- Mark Hughes
Investors
Hakia is known to have raised $11 million in its first round of funding from a panoply of investors scattered across the globe who were attracted by the company’s semantic search technology.
The New York-based company said it decided to snub the usual players in the venture capital community lining Silicon Valley’s Sand Hill Road and opted for its international connections instead, including financial firms, angel investors, and a telecommunications company.
Poland
Among them were Poland’s Prokom Investments, an investment group active in the oil, real estate, IT, financial, and biotech sectors.
Turkey
Another investor, Turkey’s KVK, distributes mobile telecom services and products in Turkey. Also from Turkey, angel investor Murat Vargi pitched in some funding. He is one of the founding shareholders in Turkcell, a mobile operator and the only Turkish company listed on the New York Stock Exchange.
Malaysia
In Malaysia, hakia secured funding from angel investor Lu Pat Ng, who represented his family, which has substantial investments in companies worldwide.
From Finland, hakia turned to Dr. Pentti Kouri, an economist and VC who was a member of the Nokia board in the 1980s. He has taught at Stanford, Yale, New York University, and HelsinkiUniversity, and worked as an economist at the International Monetary Fund. He is currently based in New York.
United States
In the United States, hakia received funding from Alexandra Investment Management, an investment advisory firm that manages a global hedge fund. Also from the U.S., former Senator and New York Knicks basketball player Bill Bradley has joined the company’s board, along with Dr. Kouri, Mr. Vargi, Anuj Mathur of Alexandra Investment Management, and hakia CEO Riza Berkan.
Hakia was on of the first alternative search engine to make the home page of web 2.0 Innovations in the past year… http://web2innovations.com/hakia.com.php
Hakia.com is the 3rd Semantic App being featured by Web2Innovations in its series of planned publications [Â ] where we will try to discover, highlight and feature the next generation of web-based semantic applications, engines, platforms, mash-ups, machines, products, services, mixtures, parsers, and approaches and far beyond.
The purpose of these publications is to discover and showcase today’s Semantic Web Apps and projects. We’re not going to rank them, because there is no way to rank these apps at this time – many are still in alpha and private beta.
Via
[ http://www.hakia.com/ ]
[ http://blog.hakia.com/ ]
[ http://www.hakia.com/about.html ]
[ http://www.readwriteweb.com/archives/hakia_takes_on_google_semantic_search.php ]
[ http://www.readwriteweb.com/archives/hakia_meaning-based_search.php ]
[ http://siteanalytics.compete.com/hakia.com/?metric=uv ]
[ http://www.internetoutsider.com/2007/07/the-big-problem.html ]
[ http://www.quantcast.com/search/hakia.com ]
[ http://www.redherring.com/Home/19789 ]
[ http://web2innovations.com/hakia.com.php ]
[ http://www.pandia.com/sew/507-hakia.html ]
[ http://www.searchenginejournal.com/hakias-semantic-search-the-answer-to-poor-keyword-based-relevancy/5246/ ]
[ http://arstechnica.com/articles/culture/hakia-semantic-search-set-to-music.ars ]
[ http://www.news.com/8301-10784_3-9800141-7.html ]
[ http://searchforbettersearch.com/ ]
[ https://web2innovations.com/money/2007/12/01/is-google-trying-to-become-a-social-search-engine/ ]
[ http://www.web2summit.com/cs/web2006/view/e_spkr/3008 ]
Â