
Based on what we are seeing the answer is close to yes. Google is now experimenting with new social features aimed at improving the users’ search experience.
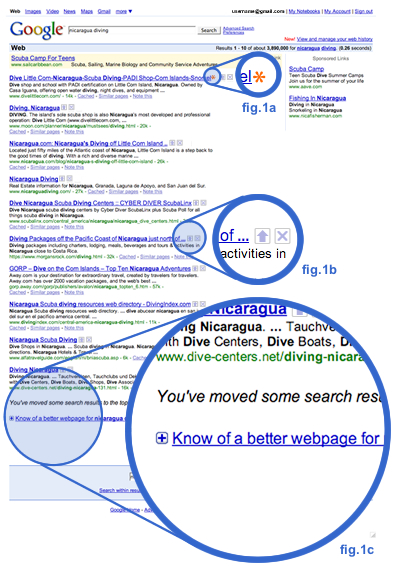
 This experiment lets you influence your search experience by adding, moving, and removing search results. When you search for the same keywords again, you’ll continue to see those changes. If you later want to revert your changes, you can undo any modifications you’ve made. Note that Google claims this is an experimental feature and may be available for only a few weeks.
This experiment lets you influence your search experience by adding, moving, and removing search results. When you search for the same keywords again, you’ll continue to see those changes. If you later want to revert your changes, you can undo any modifications you’ve made. Note that Google claims this is an experimental feature and may be available for only a few weeks.
There seems to be features like “Like itâ€, “Don’t like it?†and “Know of a better web pageâ€. Of course, to get full advantage of these extras as well as to have your recommendations associated with your searches later, upon your return, you have to be signed in.
 There is nothing new here, many of the smaller social search engines are deploying and using some of the features Google is just now trying to test, but having more than 500 million unique visitors per month, the vast majority of which are heavily using Google’s search engine, is a huge advantage if one wants to implement social elements in finding the information on web easily. Even Marissa Mayer, Google’s leading executive in search, said in August that Google would be well positioned to compete in social search. Actually with that experiment in particular it appears your vote only applies to what Google search results you will see, so it is hard to call it “social†at this time around. This may prove valuable as a stand-alone service. Also, Daniel Russell of Google, some time ago, made it pretty clear that they use user behavior to affect search results. Effectively, that’s using implicit voting, rather than explicit voting.
There is nothing new here, many of the smaller social search engines are deploying and using some of the features Google is just now trying to test, but having more than 500 million unique visitors per month, the vast majority of which are heavily using Google’s search engine, is a huge advantage if one wants to implement social elements in finding the information on web easily. Even Marissa Mayer, Google’s leading executive in search, said in August that Google would be well positioned to compete in social search. Actually with that experiment in particular it appears your vote only applies to what Google search results you will see, so it is hard to call it “social†at this time around. This may prove valuable as a stand-alone service. Also, Daniel Russell of Google, some time ago, made it pretty clear that they use user behavior to affect search results. Effectively, that’s using implicit voting, rather than explicit voting.
We think, however, the only reason Google is trying to deal with these social features, relying on humans to determine the relevancy, is their inability to effectively fight the spam their SERPs are flooded with.Â
Manipulating algorithmic based results, in one way or another is in our understanding not much harder than what you would eventually be able to do to manipulate or influence results in Google that rely and depend on social recommendations. Look at Digg for example.
We think employing humans to determine which results are best is basically an effective pathway to corruption, which is sort of worse than to have an algorithm to blame for the spam and low quality of the results. Again take a look at Digg, dmoz.org and mostly Wikipedia. Wikipedia, once a good idea, became a battle field for corporate, brand, political and social wars. Being said that, we think the problem of Google with the spam results lies down to the way how they reach to the information or more concrete the methods they use to crawl and index the vast Web. Oppositely, having people, instead of robots, gathering the quality and important information (from everyone’s point of view) from around the web is in our understanding much better and effective approach rather than having all the spam results loaded on the servers and then let the people sort them out.
That’s not the first time Google is trying new features with their search results. We remember searchmash.com. Searchmash.com is yet another of the Google’s toys in the search arena, which was quietly started out a year ago because Google did not want the public to know about this project and influence their beta testers (read: the common users) with the brand name Google. The project, however, quickly became poplar since many people discovered who the actual owner of the beta project is.
Google is under no doubt getting all the press attention they need, no matter what they do and sometimes even more than what they do actually need from. On the other hand things seem to be slowly changing today and influential media like New York Times, Newsweek, CNN and many others are in a quest for the next search engine, the next Google. This was simply impossible to happen during 2001, 2002 up to 2004, period characterized with a solid media comfort for Google’s search engine business. Â
So, is Google the first one to experiment with social search approaches, features, methods and extras? No, definitely not as you are going to see for yourself from the companies and projects listed below.
As for crediting a Digg-like system with the idea of sorting content out based on community voting, they definitely weren’t the first. The earliest implementation of this we are aware of is Kuro5hin.org (http://en.wikipedia.org/wiki/Kuro5hin), which, we think, was founded back in 1999.
One of the first and oldest companies coined social search engines on Web is Eureskter.Â
![]() Eurekster launched its community-powered social search platform “swickiâ€, as far as we know, in 2004, and explicit voting functionality in 2006. To date, over 100,000 swickis have been built, each serving a community of users passionate about a specific topic. Eurekster processes over 25,000,000 searches a month. The key to Eurekster’s success in improving relevancy here has been leveraging the explicit (and implicit) user behavior though at the group or community level, not individual or general. On the other hand Eurekster never made it to the mainstream users and somehow the company slowly faded away, lost the momentum.
Eurekster launched its community-powered social search platform “swickiâ€, as far as we know, in 2004, and explicit voting functionality in 2006. To date, over 100,000 swickis have been built, each serving a community of users passionate about a specific topic. Eurekster processes over 25,000,000 searches a month. The key to Eurekster’s success in improving relevancy here has been leveraging the explicit (and implicit) user behavior though at the group or community level, not individual or general. On the other hand Eurekster never made it to the mainstream users and somehow the company slowly faded away, lost the momentum.
Wikia was founded by Jimmy Wales (Wikipedia’s founder) and Angela Beesley in 2004.  The company is incorporated in Delaware. Gil Penchina became Wikia’s CEO in June 2006, at the same time the company moved its headquarters from St. Petersburg, Florida, to Menlo Park and later to San Mateo in California. Wikia has offices in San Mateo and New York in the US, and in PoznaÅ„ in Poland. Remote staff is also located in Chile, England, Germany, Japan, Taiwan, and also in other locations in Poland and the US. Wikia has received two rounds of investment; in March 2006 from Bessemer Venture Partners and in December 2006 from Amazon.com.
The company is incorporated in Delaware. Gil Penchina became Wikia’s CEO in June 2006, at the same time the company moved its headquarters from St. Petersburg, Florida, to Menlo Park and later to San Mateo in California. Wikia has offices in San Mateo and New York in the US, and in PoznaÅ„ in Poland. Remote staff is also located in Chile, England, Germany, Japan, Taiwan, and also in other locations in Poland and the US. Wikia has received two rounds of investment; in March 2006 from Bessemer Venture Partners and in December 2006 from Amazon.com.
According to the Wikia Search the future of Internet Search must be based on:
- Transparency – Openness in how the systems and algorithms operate, both in the form of open source licenses and open content + APIs.
- Community – Everyone is able to contribute in some way (as individuals or entire organizations), strong social and community focus.
- Quality – Significantly improve the relevancy and accuracy of search results and the searching experience.
- Privacy – Must be protected, do not store or transmit any identifying data.
Other active areas of focus include:
- Social Lab – sources for URL social reputation, experiments in wiki-style social ranking.
- Distributed Lab – projects focused on distributed computing, crawling, and indexing. Grub!
- Semantic Lab – Natural Language Processing, Text Categorization.
- Standards Lab – formats and protocols to build interoperable search technologies.
Based on who Jimmy Wales is and the success he achieved with Wikipedia therefore the resources he might have access to, Wikia Search stands at good chances to survive against any serious competition by Google.
NosyJoe is yet another great example of social search engine that employs intelligent tagging technologies and runs on a semantic platform.
 NosyJoe is a social search engine that relies on you to sniff for and submit the web’s interesting content and offers basically meaningful search results in the form of readable complete sentences and smart tags. NosyJoe is built upon the fundamental belief people are better than robots in finding the interesting, important and quality content around Web. Rather than crawling the entire Web building a massive index of information, which aside being an enormous technological task, requires huge amount of resources and is time consuming process would also load lots of unnecessary information people don’t want, NosyJoe is focused just on those parts of the Web people think are important and find interesting enough to submit and share with others.
NosyJoe is a social search engine that relies on you to sniff for and submit the web’s interesting content and offers basically meaningful search results in the form of readable complete sentences and smart tags. NosyJoe is built upon the fundamental belief people are better than robots in finding the interesting, important and quality content around Web. Rather than crawling the entire Web building a massive index of information, which aside being an enormous technological task, requires huge amount of resources and is time consuming process would also load lots of unnecessary information people don’t want, NosyJoe is focused just on those parts of the Web people think are important and find interesting enough to submit and share with others.
NosyJoe is a hybrid of a social search engine that relies on you to sniff for and submit the web’s interesting content, an intelligent content tagging engine on the back end and a basic semantic platform on its web visible part. NosyJoe then applies a semantic based textual analysis and intelligently extracts the meaningful structures like sentences, phrases, words and names from the content in order to make it just one idea more meaningfully searchable. This helps us present the search results in basically meaningful formats like readable complete sentences and smart phrasal, word and name tags.
The information is then clustered and published across the NosyJoe’s platform into contextual channels, time and source categories and semantic phrasal, name and word tags are also applied to meaningfully connect them together, which makes even the smallest content component web visible, indexable and findable. At the end a set of algorithms and user patterns are applied to further rank, organize and share the information.
From our quick tests on the site the search results returned were presented in form of meaningful sentences and semantic phrasal tags (as an option), which turns their search results into — something we have never seen on web so far — neat content components, readable and easily understandable sentences, unlike what we are all used to, some excerpts from the content where the keyword is found in. When compared to other search engines’ results NosyJoe.com’s SERPs appear truly meaningful.
As of today, and just 6 or 7 months since they went online, NosyJoe is already having more than 500,000 semantic tags created that connect tens of thousands of meaningful sentences across their platform.
We have no information as to who stays behind NosyJoe but the project seems very serious and promising in many aspects from how they gather the information to how they present the results to the way they offset low quality results. From all newcomers social search engines NosyJoe stands at best changes to make it. As far as we know NosyJoe is also based in the Silicon Valley.Â
Sproose says it is developing search technology that lets users obtain personalized results, ![]() which can be shared among a social network, using the Nutch open-source search engine, and building applications on top. Their search appears to using third party search feeds and ranks the results based on the users’ votes.
which can be shared among a social network, using the Nutch open-source search engine, and building applications on top. Their search appears to using third party search feeds and ranks the results based on the users’ votes.
Sproose is said it has raised nearly $1 million in seed funding. It is based in Danville, a town on the east side of the SF Bay Area. Sproose said Roger Smith, founder, former president and chief executive at Silicon Valley Bank, was one of the angel investors, and is joining Sproose’s board.
Other start-up search engines of great variety are listed below:
- Hakia – Relies on natural language processing. These guys are also experimenting with social elements with the feature so called “meet others who asked the same query“.
- Quintura – A visual engine based today in Virginia, US. The company is founded by Russians and has early been headquartered in Moscow.Â
- Mahalo – search engine that looks more like a directory with quality content handpicked by editors. Jason Calacanis is the founder of the company.
- ChaCha – Real humans try to help you in your quest for information, via chat. The company is based in Indiana and has been criticized a lot by the Silicon Valley’s IT community. Despite these critics they have recently raised $10m in Series A round of funding.Â
- Powerset – Still in closed beta and also relying on understanding the natural language. See our Powerset review. Â
- Clusty – founded in 2000 by three Carnegie Mellon University scientists.
- Lexxe – Sydney based engine featuring natural language processing technologies.
- Accoona – The company has recently filed for an IPO in US planning to raise $80M from the public.
- Squidoo – It has been started in October 2005 by Seth Godin and looks more like a wiki site, ala Wikia or Wikipedia where anyone creates articles on different topics.
- Spock – Focuses on people information, people search engine.
One thing is for sure today; Google is now bringing solid credentials to and is somehow legitimating the social search approach, which by the way is helping those so many smaller so-called social search engines.Â
Perhaps it is about time for consolidation in the social search sector. Some of the smaller but more promising social search engines can now become one in order to be able to compete with and prevent Google’s dominance within the social search sector too, just like what they did with the algorithmic search engines. Is Google also interested in? Anyone heard of recent interest in or already closed acquisition deals for start-up social search engines?
On the contrary, more and more IT experts, evangelists and web professionals agree on the fact that taking Google down is a challenge that will most likely be accomplished by a concept that is anything else but not a search engine in our traditional understanding. Such concepts, including but not limited to, are Wikipedia, Del.icio.us and LinkedWords. In other words finding information on web doesn’t necessarily mean to search for it.
[ http://www.google.com/experimental/a840e102.html ]
[ http://www.blueverse.com/2007/12/01/google-the-social-…]
[ http://www.adesblog.com/2007/11/30/google-experimenting-social…Â ]
[ http://www.techcrunch.com/2007/11/28/straight-out-of-left-field-google-experimenting-with-digg-style-voting-on-search-results ]
[ http://www.blogforward.com/money/2007/11/29/google… ]
[ http://nextnetnews.blogspot.com/2007/09/is-nosyjoecom-… ]
[ http://www.newsweek.com/id/62254/page/1 ]
[ http://altsearchengines.com/2007/10/05/the-top-10-stealth-… ]
[ http://www.nytimes.com/2007/06/24/business/yourmoney/…Â Â ]
[ http://dondodge.typepad.com/the_next_big_thing/2007/05… ]
[ http://search.wikia.com/wiki/Search_Wikia ]
[ http://nosyjoe.com/about.com ]
[ http://www.siliconbeat.com/entries/2005/11/08/sproose_up_your…Â ]
[ http://nextnetnews.blogspot.com/2007/10/quest-for-3rd-generation… ]
[ http://www.sproose.com ]