In our planned series of publications about the Semantic Web and its apps today Powerset is going to be our second company, after Freebase, to be featured.Â
Powerset is a Silicon Valley based company building a transformative consumer search engine based on natural language processing. Their unique innovations in search are rooted in breakthrough technologies that take advantage of the  structure and nuances of natural language. Using these advanced techniques, Powerset is building a large-scale search engine that breaks the confines of keyword search. By making search more natural and intuitive, Powerset is fundamentally changing how we search the web, and delivering higher quality results.
structure and nuances of natural language. Using these advanced techniques, Powerset is building a large-scale search engine that breaks the confines of keyword search. By making search more natural and intuitive, Powerset is fundamentally changing how we search the web, and delivering higher quality results.
Powerset’s search engine is currently under development and is closed for the general public. You can always keep an eye on them in order to learn more information about their technology and approach.
Despite all the press attention Powerset is gaining there are too few details publicly available for the search engine. In fact Powerset is lately one of the most buzzed companies in the Silicon Valley, for good or bad.
Power set is a term from the mathematics and means a set S, the power set (or powerset) of S, written P(S) P(S), or 2S, is the set of all subsets of S. In axiomatic set theory (as developed e.g. in the ZFC axioms), the existence of the power set of any set is postulated by the axiom of power set. Any subset F of P(S), is called a family of sets over S.
From the latest information publicly available for Powerset we learn that, just like some other start-up search engines, they are also using Hbase in Hadoop environment to process vast amounts of data.
It also appears that Powerset relies on a number of proprietary technologies such as the XLE, licensed from PARC, ranking algorithms, and the ever-important onomasticon (a list of proper nouns naming persons or places).
  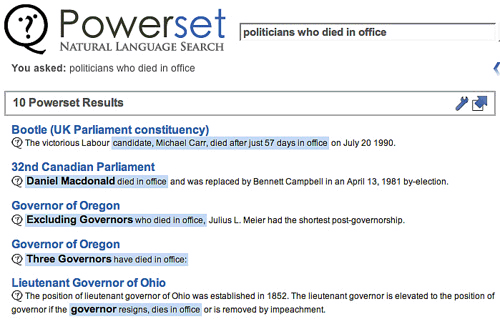
For any other component, Powerset tries to use open source software whenever available. One of the unsung heroes that form the foundation for all of these components is the ability to process insane amounts of data. This is especially true for a Natural Language search engine. A typical keyword search engine will gather hundreds of terabytes of raw data to index the Web. Then, that raw data is analyzed to create a similar amount of secondary data, which is used to rank search results. Since Powerset’s technology creates a massive amount of secondary data through its deep language analysis, Powerset will be generating far more data than a typical search engine, eventually ranging up to petabytes of data.
Powerset has already benefited greatly from the use of Hadoop: their index build process is entirely based on a Hadoop cluster running the Hadoop Distributed File System (HDFS) and makes use of Hadoop’s map/reduce features.
In fact Google also uses a number of well-known components to fulfill their enormous data processing needs: a distributed file system (GFS) ( http://labs.google.com/papers/gfs.html ), Map/Reduce ( http://labs.google.com/papers/mapreduce.html ), and BigTable ( http://labs.google.com/papers/bigtable.html ).
Hbase is actually the open-source equivalent of Google’s Bigtable, which, as far as we understand the matter is a great technological achievement of the guys behind Powerset. Both JimKellerman and Michael Stack are from Powerset and are the initial contributors of Hbase.
Hbase could be the panacea for Powerset in scaling their index up to Google’s level, yet coping Google’s approach is perhaps not the right direction for a small technological company like Powerset. We wonder if Cuill, yet another start-up search engine that’s claiming to have invented a technology for cheaper and faster indexation than Google’s, has built their architecture upon the Hbase/Hadoop environment. Cuill claims that their indexing costs will be 1/10th of Google’s, based on new search architectures and relevance methods. If it is true what would the Powerset costs then be considering the fact that Powerset is probably having higher indexing costs even compared to Google, because it does a deep contextual analysis on every sentence on every web page? Taking into consideration that Google is having more than 450,000 servers in several major data centers and Powerset’s indexing and storage costs might be even higher the approach Powerset is taking might be costly business for their investors.
Unless Hbase and Hadoop are the secret answer Powerset relies on to significantly reduce the costs.Â
Hadoop is an interesting software platform that lets one easily write and run applications that process vast amounts of data.
Here’s what makes Hadoop especially useful:
- Scalable: Hadoop can reliably store and process petabytes.
- Economical: It distributes the data and processing across clusters of commonly available computers. These clusters can number into the thousands of nodes.
- Efficient: By distributing the data, Hadoop can process it in parallel on the nodes where the data is located. This makes it extremely rapid.
- Reliable: Hadoop automatically maintains multiple copies of data and automatically redeploys computing tasks based on failures.
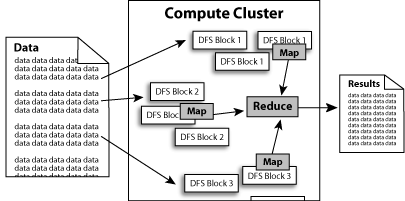 Hadoop implements MapReduce, using the Hadoop Distributed File System (HDFS) (see figure below.) MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located.
Hadoop implements MapReduce, using the Hadoop Distributed File System (HDFS) (see figure below.) MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located.
Hadoop has been demonstrated on clusters with 2000 nodes. The current design target is 10,000 node clusters.
Hadoop is a Lucene sub-project that contains the distributed computing platform that was formerly a part of Nutch.
Hbase’s background
Google’s Bigtable, a distributed storage system for structured data, is a very effective mechanism for storing very large amounts of data in a distributed environment. Just as Bigtable leverages the distributed data storage provided by the Google File System, Hbase will provide Bigtable-like capabilities on top of Hadoop. Data is organized into tables, rows and columns, but a query language like SQL is not supported. Instead, an Iterator-like interface is available for scanning through a row range (and of course there is an ability to retrieve a column value for a specific key). Any particular column may have multiple values for the same row key. A secondary key can be provided to select a particular value or an Iterator can be set up to scan through the key-value pairs for that column given a specific row key.
Reach
According to Quantcast, Powerset is basically not popular site and is reaching less than 20,000 unique visitors per month, around 10,000 Americans. Compete is reporting the same – slightly more than 20,000 uniques per month. Considering the fact the search engine is still in its alpha stage these numbers are not that bad.
The People
Powerset has assembled a star team of talented engineers, researchers, product innovators and entrepreneurs to realize an ambitious vision for the future of search. Our team comprises industry leaders from a diverse set of companies including: Altavista, Apple, Ask.com, BBN, Digital, IDEO, IBM, Microsoft, NASA, PARC, Promptu, SRI, Tellme, Whizbang! Labs, and Yahoo!.
Founders of Powerset are Barney Pell and Lorenzo Thione and the company is actually headquartered in San Francisco. Recently Barney Pell has stepped down from the CEO spot and is now the company’s CTO.
 Barney Pell, Ph.D. (CTO) For over 15 years Barney Pell (Ph.D. Computer science, Cambridge University 1993) has pursued groundbreaking technical and commercial innovation in A.I. and Natural Language understanding at research institutions including NASA, SRI, Stanford University and Cambridge University. In startup companies, Dr. Pell was Chief Strategist and VP of Business Development at StockMaster.com (acquired by Red Herring in March, 2000) and later had the same role at Whizbang! Labs. Just prior to Powerset, Pell was an Entrepreneur in Residence at Mayfield, one of the top VC firms in Silicon Valley.
Barney Pell, Ph.D. (CTO) For over 15 years Barney Pell (Ph.D. Computer science, Cambridge University 1993) has pursued groundbreaking technical and commercial innovation in A.I. and Natural Language understanding at research institutions including NASA, SRI, Stanford University and Cambridge University. In startup companies, Dr. Pell was Chief Strategist and VP of Business Development at StockMaster.com (acquired by Red Herring in March, 2000) and later had the same role at Whizbang! Labs. Just prior to Powerset, Pell was an Entrepreneur in Residence at Mayfield, one of the top VC firms in Silicon Valley.
 Lorenzo Thione (Product Architect) Mr. Thione brings to Powerset years of research experience in computational linguistics and search from Research Scientist positions at the CommerceNet consortium and the Fuji-Xerox Palo Alto Laboratory. His main research focus has been discourse parsing and document analysis, automatic summarization, question answering and natural language search, and information retrieval. He has co-authored publications in the field of computational linguistics and is a named inventor on 13 worldwide patent applications spanning the fields of computational linguistics, mobile user interfaces, search and information retrieval, speech technology, security and distributed computing. A native of Milan, Italy, Mr. Thione holds a Masters in Software Engineering from the University of Texas at Austin.
Lorenzo Thione (Product Architect) Mr. Thione brings to Powerset years of research experience in computational linguistics and search from Research Scientist positions at the CommerceNet consortium and the Fuji-Xerox Palo Alto Laboratory. His main research focus has been discourse parsing and document analysis, automatic summarization, question answering and natural language search, and information retrieval. He has co-authored publications in the field of computational linguistics and is a named inventor on 13 worldwide patent applications spanning the fields of computational linguistics, mobile user interfaces, search and information retrieval, speech technology, security and distributed computing. A native of Milan, Italy, Mr. Thione holds a Masters in Software Engineering from the University of Texas at Austin.
Board of Directors
Aside Barney Pell, who is also serving on the company’s board of directors, other board members are:
Charles Moldow (BOD) is a general partner at Foundation Capital. He joined Foundation on the heels of successfully building two companies from early start-up through greater than $100 million in sales. Most notably, Charles led Tellme Networks in raising one of the largest private financing rounds in the country post Internet bubble, adding $125 million in cash to the company balance sheet during tough market conditions in August, 2000. Prior to Tellme, Charles was a member of the founding team of Internet access provider @Home Network. In 1998, Charles assisted in the $7 billion acquisition of Excite Network. After the merger, Charles became General Manager of Matchlogic, the $80 million division focused on interactive advertising.
Peter Thiel (BOD) is a partner at Founders Fund VC Firm in San Francisco. In 1998, Peter co-founded PayPal and served as its Chairman and CEO until the company’s sale to eBay in October 2002 for $1.5 billion. Peter’s experience in finance includes managing a successful hedge fund, trading derivatives at CS Financial Products, and practicing securities law at Sullivan & Cromwell. Peter received his BA in Philosophy and his JD from Stanford.
Investors
In June 2007 Powerset has raised $12.5M in series A round of funding from Foundation Capital and The Founder’s Fund. Early investors include Eric Tilenius and Peter Thiel, who is also early investor in Facebook.com. Other early investors are as follows:
CommerceNet is an entrepreneurial research institute focused on making the world a better place by fulfilling the promise of the Internet. CommerceNet invests in exceptional people with bold ideas, freeing them to pursue visions outside the comfort zone of research labs and venture funds and share in their success.
Dr. Tenenbaum is a world-renowned Internet commerce pioneer and visionary. He was founder and CEO of Enterprise Integration Technologies, the first company to conduct a commercial Internet transaction (1992), secure Web transaction (1993) and Internet auction (1993). In 1994, he founded CommerceNet to accelerate business use of the Internet. In 1997, he co-founded Veo Systems, the company that pioneered the use of XML for automating business-to-business transactions. Dr. Tenenbaum joined Commerce One in January 1999, when it acquired Veo Systems. As Chief Scientist, he was instrumental in shaping the company’s business and technology strategies for the Global Trading Web. Earlier in his career, Dr. Tenenbaum was a prominent AI researcher, and led AI research groups at SRI International and Schlumberger Ltd. Dr. Tenenbaum is a Fellow and former board member of the American Association for Artificial Intelligence, and a former Consulting Professor of Computer Science at Stanford. He currently serves as an officer and director of Webify Solutions and Medstory Inc., and is a Consulting Professor of Information Technology at Carnegie Mellon’s new West Coast campus. Dr. Tenenbaum holds B.S. and M.S. degrees in Electrical Engineering from MIT, and a Ph.D. from Stanford.Â
Allan Schiffman was CTO and founder of Terisa Systems, a pioneer in communications security Technology to the Web software industry. Earlier, Mr. Schiffman was Chief Technology Officer at Enterprise Integration Technologies, a pioneer in the development of key security protocols for electronic commerce over the Internet. In these roles, Mr. Schiffman has raised industry awareness of role for security and public key cryptography in ecommerce by giving more than thirty public lectures and tutorials. Mr. Schiffman was also a member of the team that designed the Secure Electronic Transactions (SET) payment card protocol commissioned by MasterCard and Visa. Mr. Schiffman co-designed the first security protocol for the Web, the Secure HyperText Transfer Protocol (S-HTTP). Mr. Schiffman led the development of the first secure Web browser, Secure Mosaic, which was fielded to CommerceNet members for ecommerce trials in 1994. Earlier in his career, Mr. Schiffman led the development of a family of high-performance Smalltalk implementations that gained both academic recognition and commercial success. These systems included several innovations widely adopted by other object-oriented language implementers, such as the “just-in-time compilation†technique universally used by current Java virtual machines. Mr. Schiffman holds an M.S. in Computer Science from Stanford University.
Rob Rodin is the Chairman and CEO of RDN Group; strategic advisors focused on corporate transitions, customer interface, sales and marketing, distribution and supply chain management. Additionally, he serves as Vice Chairman, Executive Director and Chairman of the Investment Committee of CommerceNet which researches and funds open platform, interoperable business services to advance commerce. Prior to these positions, Mr. Rodin served as CEO and President of Marshall Industries, where he engineered the reinvention of the company, turning a conventionally successful $500 million distributor into a web enabled $2 billion global competitor. “Free, Perfect and Now: Connecting to the Three Insatiable Customer Demandsâ€, Mr. Rodin’s bestselling book, chronicles the radical transformation of Marshall Industries.Â
The Founders Fund – The Founders Fund, L.P. is a San Francisco-based venture capital fund that focuses primarily on early-stage, high-growth investment opportunities in the technology sector. The Fund’s management team is composed of investors and entrepreneurs with relevant expertise in venture capital, finance, and Internet technology. Members of the management team previously led PayPal, Inc. through several rounds of private financing, a private merger, an initial public offering, a secondary offering, and its eventual sale to eBay, Inc. The Founders Fund possesses the four key attributes that well-position it for success: access to elite research universities, contact to entrepreneurs, operational and financial expertise, and the ability to pick winners. Currently, the Founders Fund is invested in over 20 companies, including Facebook, Ironport, Koders, Engage, and the newly-acquired CipherTrust.Â
Amidzad – Amidzad is a seed and early-stage venture capital firm focused on investing in emerging growth companies on the West Coast, with over 50 years of combined entrepreneurial experience in building profitable, global enterprises from the ground up and over 25 years of combined investing experience in successful information technology and life science companies. Over the years, Amidzad has assembled a world-class network of serial entrepreneurs, strategic investors, and industry leaders who actively assist portfolio companies as Entrepreneur Partners and Advisors.Amidzad has invested in companies like Danger, BIX, Songbird, Melodis, Freewebs, Agitar, Affinity Circles, Litescape and Picaboo.
Eric Tilenius brings a two-decade track record that combines venture capital, startup, and industry-leading technology company experience. Eric has made over a dozen investments in early-stage technology, internet, and consumer start-ups around the globe through his investment firm, Tilenius Ventures. Prior to forming Tilenius Ventures, Eric was CEO of Answers Corporation (NASDAQ: ANSW), which runs Answers.com, one of the leading information sites on the internet. He previously was an entrepreneur-in-residence at venture firm Mayfield. Prior to Mayfield, Eric was co-founder, CEO, and Chairman of Netcentives Inc., a leading loyalty, direct, and promotional internet marketing firm. Eric holds an MBA from the Stanford University Graduate School of Business, where he graduated as an Arjay Miller scholar, and an undergraduate degree in economics, summa cum laude, from Princeton University.
Esther Dyson does business as EDventure, the reclaimed name of the company she owned for 20-odd years before selling it to CNET Networks in 2004. Her primary activity is investing in start-ups and guiding many of them as a board member. Her board seats include Boxbe, CVO Group (Hungary), Eventful.com, Evernote, IBS Group (Russia, advisory board), Meetup, Midentity (UK), NewspaperDirect, Voxiva, Yandex (Russia)… and WPP Group (not a start-up). Some of her other past IT investments include Flickr and Del.icio.us (sold to Yahoo!), BrightMail (sold to Symantec), Medstory (sold to Microsoft), Orbitz (sold to Cendant and later re-IPOed). Her current holdings include ActiveWeave, BlogAds, ChoiceStream, Democracy Machine, Dotomi, Linkstorm, Ovusoft, Plazes, Powerset, Resilient, Tacit, Technorati, Visible Path, Vizu.com and Zedo. On the non-profit side, Dyson sits on the boards of the Eurasia Foundation, the National Endowment for Democracy, the Santa Fe Institute and the Sunlight Foundation. She also blogs occasionally for the Huffington Post, as Release 0.9.
Adrian Weller – Adrian graduated in 1991 with first class honours in mathematics from Trinity College, Cambridge, where he met Barney. He moved to NY, ran Goldman Sachs’ US Treasury options trading desk and then joined the fixed income arbitrage trading group at Salomon Brothers. He went on to run US and European interest rate trading at Citadel Investment Group in Chicago and London. Recently, Adrian has been traveling, studying and managing private investments. He resides in Dublin with his wife, Laura and baby daughter, Rachel.
Azeem Azhar – Azeem is currently a technology executive focussed on corporate innovation at a large multinational. He began his career as a technology writer, first at The Guardian and then The Economist . While at The Economist, he launched Economist.com. Since then, he has been involved with several internet and technology businesses including launching BBC Online and founding esouk.com, an incubator. He was Chief Marketing Officer for Albert-Inc, a Swiss AI/natural language processing search company and UK MD of 20six, a blogging service. He has advised several internet start-ups including Mondus, Uvine and Planet Out Partners, where he sat on the board. He has a degree in Philosophy, Politics and Economics from Oxford University. He currently sits on the board of Inuk Networks, which operates a IPTV broadcast platform. Azeem lives in London with his wife and son.
Todd Parker – Since 2002, Mr. Parker has been a Managing Director at Hidden River, LLC, a firm specializing in Mergers and Acquisitions consulting services to the wireless and communications industry. Previously and from 2000 to 2002, Mr. Parker was the founder and CEO of HR One, a human resources solutions provider and software company. Mr. Parker has also held senior executive and general manager positions with AirTouch Corporation where he managed over 15 corporate transactions and joint venture formations with a total value of over $6 billion. Prior to AirTouch, Mr. Parker worked for Arthur D. Littleas a consultant. Mr. Parker earned a BS from Babson College in Entrepreneurial Studies and Communications.
Powerset.com is the 2nd Semantic App being featured by Web2Innovations in its series of planned publications where we will try to discover, highlight and feature the next generation of web-based semantic applications, engines, platforms, mash-ups, machines, products, services, mixtures, parsers, and approaches and far beyond.
The purpose of these publications is to discover and showcase today’s Semantic Web Apps and projects. We’re not going to rank them, because there is no way to rank these apps at this time – many are still in alpha and private beta.
Via
[ http://www.powerset.com ]
[ http://www.powerset.com/about ]
[ http://en.wikipedia.org/wiki/Power_set ]
[ http://en.wikipedia.org/wiki/Powerset ]
[ http://blog.powerset.com/ ]
[ http://lucene.apache.org/hadoop/index.html ]
[ http://wiki.apache.org/lucene-hadoop/Hbase ]
[ http://blog.powerset.com/2007/10/16/powerset-empowered-by-hadoop ]
[ http://www.techcrunch.com/2007/09/04/cuill-super-stealth-search-engine-google-has-definitely-noticed/ ]
[ http://www.barneypell.com/ ]
[ http://valleywag.com/tech/rumormonger/hanky+panky-ousts-pell-as-powerset-ceo-318396.php ]
[ http://www.crunchbase.com/company/powerset ]

 Already, Freebase covers millions of topics in hundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz, and the SEC archives, it contains structured information on many popular topics, including movies, music, people and locations – all reconciled and freely available via an open API. This information is supplemented by the efforts of a passionate global community of users who are working together to add structured information on everything from philosophy to European railway stations to the chemical properties of common food ingredients.
Already, Freebase covers millions of topics in hundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz, and the SEC archives, it contains structured information on many popular topics, including movies, music, people and locations – all reconciled and freely available via an open API. This information is supplemented by the efforts of a passionate global community of users who are working together to add structured information on everything from philosophy to European railway stations to the chemical properties of common food ingredients.
 He is the author of several articles in this area, including the book Fuzzy Systems Design Principles published by IEEE in 1997. Before launching hakia, Dr. Berkan worked for the U.S. Government for a decade with emphasis on information handling, criticality safety and safeguards. He holds a Ph.D. in Nuclear Engineering from the University of Tennessee, and B.S. in Physics from Hacettepe University, Turkey. He has been developing the company’s semantic search technology with help from Professor Victor Raskin of PurdueUniversity, who specializes in computational linguistics and ontological semantics, and is the company’s chief scientific advisor.
He is the author of several articles in this area, including the book Fuzzy Systems Design Principles published by IEEE in 1997. Before launching hakia, Dr. Berkan worked for the U.S. Government for a decade with emphasis on information handling, criticality safety and safeguards. He holds a Ph.D. in Nuclear Engineering from the University of Tennessee, and B.S. in Physics from Hacettepe University, Turkey. He has been developing the company’s semantic search technology with help from Professor Victor Raskin of PurdueUniversity, who specializes in computational linguistics and ontological semantics, and is the company’s chief scientific advisor. William Daniel “Danny” Hillis (born September 25, 1956, in Baltimore, Maryland) is an American inventor, entrepreneur, and author. He co-founded Thinking Machines Corporation, a company that developed the Connection Machine, a parallel supercomputer designed by Hillis at MIT. He is also co-founder of the Long Now Foundation, Applied Minds, Metaweb Technologies, and author of The Pattern on the Stone: The Simple Ideas That Make Computers Work.
William Daniel “Danny” Hillis (born September 25, 1956, in Baltimore, Maryland) is an American inventor, entrepreneur, and author. He co-founded Thinking Machines Corporation, a company that developed the Connection Machine, a parallel supercomputer designed by Hillis at MIT. He is also co-founder of the Long Now Foundation, Applied Minds, Metaweb Technologies, and author of The Pattern on the Stone: The Simple Ideas That Make Computers Work. We are not going to try to explain in details what Semantic Web is after all. There has been plenty of information on web as to what does really that term mean. First off it is the Tim Berners-Lee W3C led initiative that touts technologies like
We are not going to try to explain in details what Semantic Web is after all. There has been plenty of information on web as to what does really that term mean. First off it is the Tim Berners-Lee W3C led initiative that touts technologies like